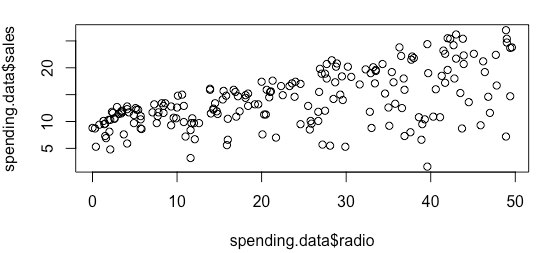
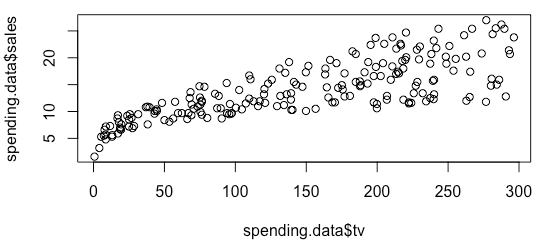
Residual standard error: 4.275 on 198 degrees of freedom Multiple R-squared: 0.332, Adjusted R-squared: 0.3287 F-statistic: 98.42 on 1 and 198 DF, p-value: < 2.2e-16
1.2 Accounting for multiple predictors: multiple linear regression
> regression <- lm(sales ~ radio + tv, data=spending.data)
> summary(regression)
Call: lm(formula = sales ~ radio + tv, data = spending.data)
Residuals: Min 1Q Median 3Q Max -8.7977 -0.8752 0.2422 1.1708 2.8328
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 2.92110 0.29449 9.919 <2e-16 *** radio 0.18799 0.00804 23.382 <2e-16 *** tv 0.04575 0.00139 32.909 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.681 on 197 degrees of freedom Multiple R-squared: 0.8972, Adjusted R-squared: 0.8962 F-statistic: 859.6 on 2 and 197 DF, p-value: < 2.2e-16
1.3 Allocating marketing budgets
1.3.1 Ratio of elasticities method
What is elasticity?
% change in the response variable for a 1% change in the predictor variable
Example: the % change in sales for a 1% change in advertising spending
Let us start with an example:
Image that you have a £100,000 budget to spend on advertising
A 1% increase in online advertising increases sales by 0.12%
A 1% increase in offline advertising increases sales by 0.08%
Residual standard error: 0.1254 on 196 degrees of freedom Multiple R-squared: 0.9098, Adjusted R-squared: 0.9084 F-statistic: 658.7 on 3 and 196 DF, p-value: < 2.2e-16
我们已经将0.01添加到广播的值上,因为广播的最小值是0,这样做会导致对log(广播)的无效结果。
哪个模型更好,线性模型还是对数-对数模型?
绘制变量之间的关系图
比较线性模型和对数-对数模型的拟合情况
如何解释系数?
广播广告的增加1%导致销售额增加0.14%。
电视广告的增加1%导致销售额增加0.35%。
Coefficients are elasticities!
Summary
Linear • Equation: Y = β0 + β1X • Interpretation: One unit change in X leads to beta1 unit change in Y • When to use? Linear relation between X and Y Log-Log • Equation: log(Y) = β0 + β1log(X) • Interpretation: One percent change in X leads to β1 percent change in Y • When to use? A non-linear relation between X and Y Which one to use? • Plot the data to learn about the relation between X and Y. • Estimate both models and identify the best fitting model
2.2 Modelling media synergy
营销组合工具的综合使用可以产生协同效应。
当多种媒体的联合影响超过它们各自部分的总和时,就会产生协同效应。
Is TV advertising more effective in the presence of radio advertising?
Residual standard error: 0.1043 on 195 degrees of freedom Multiple R-squared: 0.938, Adjusted R-squared: 0.9367 F-statistic: 737 on 4 and 195 DF, p-value: < 2.2e-16
使用中心化变量
> center <- function(x) { scale(x, scale = F)} # scale = F, means only center not standardize
Residual standard error: 0.1043 on 195 degrees of freedom Multiple R-squared: 0.938, Adjusted R-squared: 0.9367 F-statistic: 737 on 4 and 195 DF, p-value: < 2.2e-16
> # filter() function from stats package applies linear filtering to a univariate time series > > spending.data <- spending.data %>% mutate(tv_adstoc .... [TRUNCATED]
Residual standard error: 0.1604 on 196 degrees of freedom Multiple R-squared: 0.8523, Adjusted R-squared: 0.8501 F-statistic: 377.1 on 3 and 196 DF, p-value: < 2.2e-16
2.4 Predictive accuracy *
> # Total number of rows in the data frame > n <- nrow(spending.data)
> # Number of rows for the training set (80% of the dataset) > n_train <- round(0.80 * n) # Training data
> spending.data.train <- subset(spending.data, week <= n_train) # Holdout data
Residual standard error: 0.1483 on 156 degrees of freedom Multiple R-squared: 0.8812, Adjusted R-squared: 0.8789 F-statistic: 385.6 on 3 and 156 DF, p-value: < 2.2e-16
> # Predict sales on holdout data > spending.data.holdout$predicted_sales_log <- + predict(object =regression, newdata = spending.data.holdout)
> # Convert predicted log sales to actual sales > spending.data.holdout$predicted_sales <- exp(spending.data.holdout$predicted_sales_log)
> # Quantify predictive accuracy: Mean Average Percentage Error (MAPE) > mape <- mean(abs((spending.data.holdout$sales -spending.data.holdout$predicte .... [TRUNCATED]
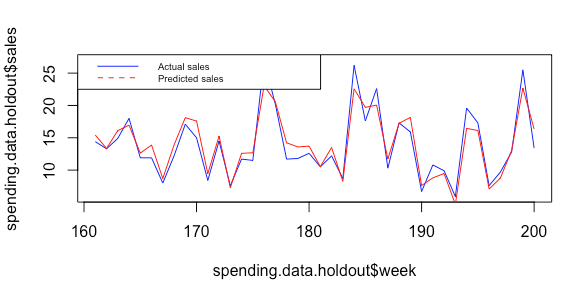
> mape # Reflects the average percentage error in a given week [1] 0.1010304
> # Plot actual versus predicted sales > plot(spending.data.holdout$week, spending.data.holdout$sales, type="l", col="blue") # Plot actual sales
> lines(spending.data.holdout$week,spending.data.holdout$predicted_sales, type = "l", col = "red") # Add predicted sales