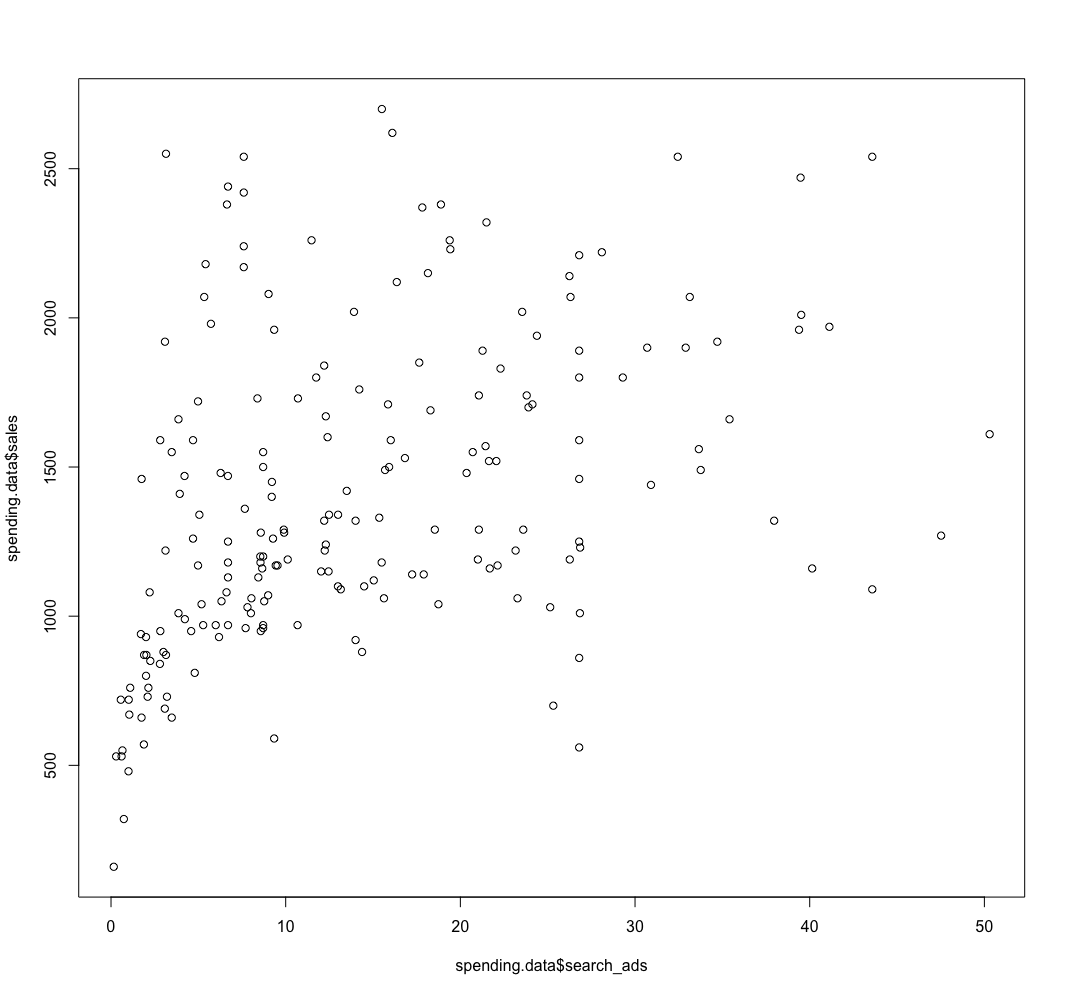
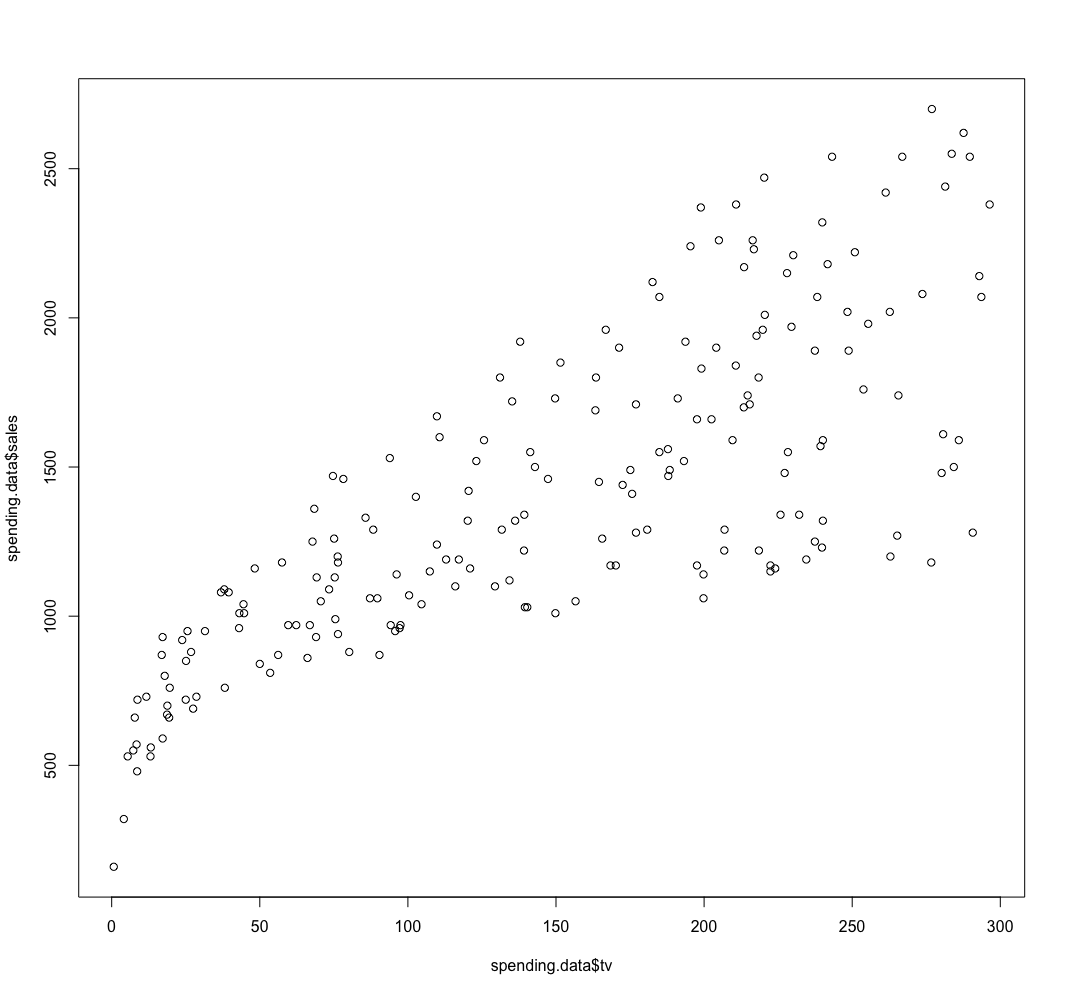
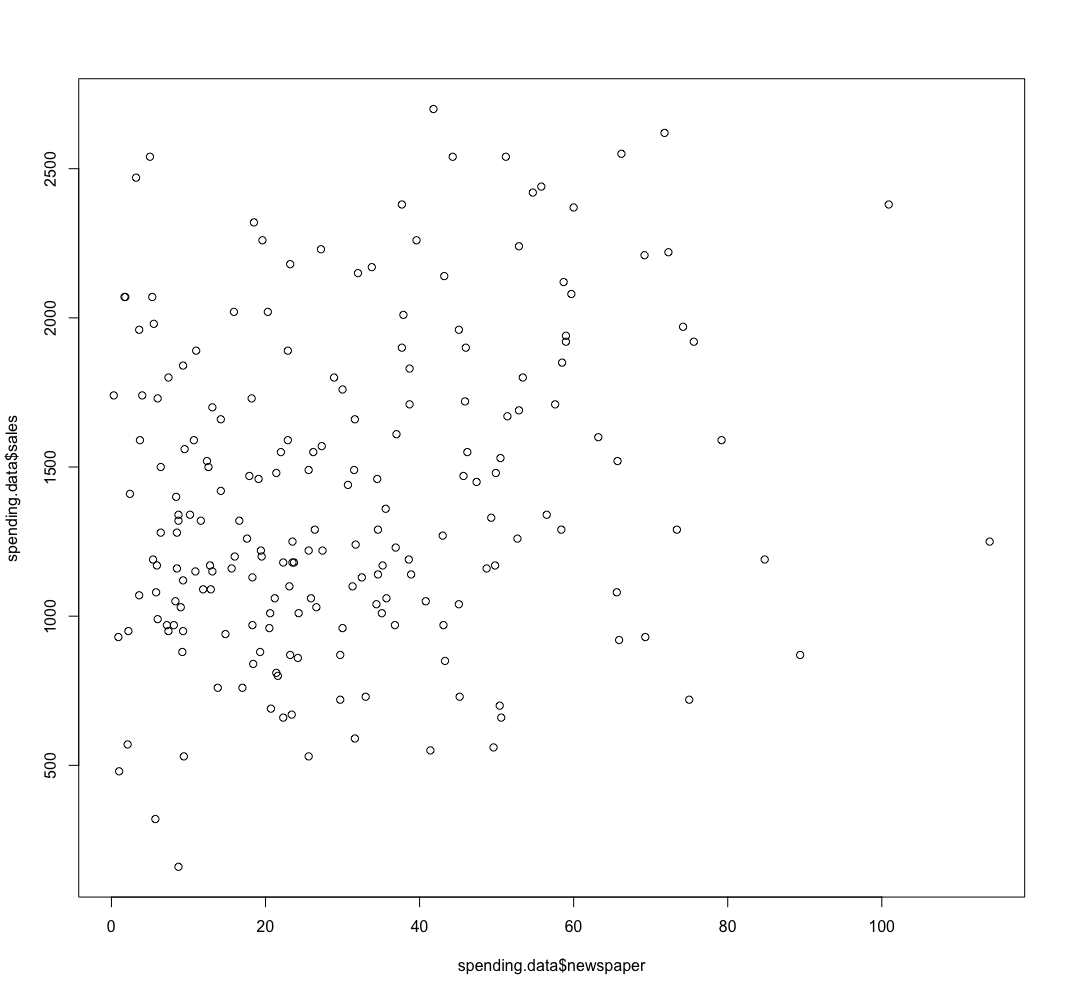
R: 4.3.2 (2023-10-31)
R studio: 2023.12.1+402 (2023.12.1+402)
1. Manage customer hierarchical
1.1 segmentation
According to the demographics data provided, ‘Emplyment’ data was excluded because it was related to salary. The data with ‘salary=7’ was removed because it was invalid. ‘Regions’ are simplified to 3. Finally the continuous vectors are normalized and the ordinal variables are factored.
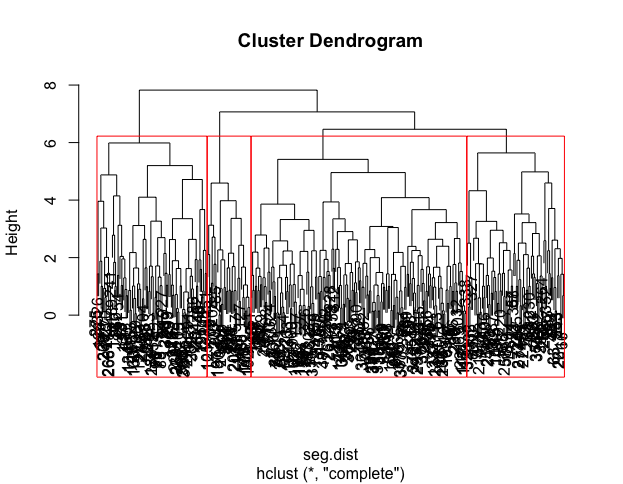
Considering data contains ordinal varibles and continous variables, we segment customers into four groups based on hierarchical clustering, which differentiation between groups was more appropriate than three or five groups.
1.1.1 import and check data
> seg.df <- read.csv("1_demographics.csv", stringsAsFactors = TRUE) > head(seg.df, n = 5) Consumer_id Age_Group Gender Salary Education Employment Location_by_region Choco_Consumption 1 352 1 2 1 2 3 4 0 2 103 3 2 3 1 1 1 1 3 17 1 1 1 1 4 1 1 4 66 1 1 1 1 3 1 1 5 329 2 1 1 1 8 1 1 Sustainability_Score 1 -1.15059 2 0.50287 3 -1.14517 4 -0.46688 5 -2.08817 > summary(seg.df, digits = 2) Consumer_id Age_Group Gender Salary Education Employment Location_by_region Min. : 1 Min. :1.0 Min. :1.0 Min. :0.0 Min. :1.0 Min. : 1.0 Min. :1.0 1st Qu.: 95 1st Qu.:1.0 1st Qu.:1.0 1st Qu.:1.0 1st Qu.:2.0 1st Qu.: 1.0 1st Qu.:1.0 Median :190 Median :2.0 Median :2.0 Median :2.0 Median :2.0 Median : 2.0 Median :1.0 Mean :190 Mean :2.2 Mean :1.7 Mean :2.3 Mean :2.3 Mean : 2.4 Mean :1.3 3rd Qu.:284 3rd Qu.:3.0 3rd Qu.:2.0 3rd Qu.:3.0 3rd Qu.:3.0 3rd Qu.: 3.0 3rd Qu.:1.0 Max. :378 Max. :4.0 Max. :2.0 Max. :7.0 Max. :4.0 Max. :10.0 Max. :8.0 Choco_Consumption Sustainability_Score Min. :0 Min. :-3.26 1st Qu.:2 1st Qu.:-0.61 Median :3 Median : 0.14 Mean :3 Mean : 0.00 3rd Qu.:4 3rd Qu.: 0.68 Max. :5 Max. : 2.04 > > ### 1.1.1 remove consumer_id in data set, and set consumer_id as row name > rownames(seg.df) <- seg.df[, 1] > seg.df <- seg.df[, -1] > #### remove salary = 7, invalid data > seg.df <- seg.df[seg.df$Salary != 7, ] > #### remove Employment, which related to Salary > seg.df <- subset(seg.df, select = -Employment) > #### just split region to 3 groups > seg.df$Location_by_region[seg.df$Location_by_region > 2] <- 3
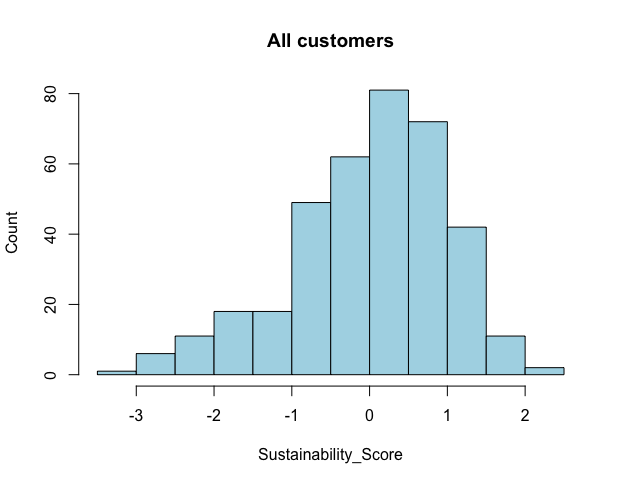
hist(seg.df$Sustainability_Score, main = "All customers", xlab = "Sustainability_Score", ylab = "Count", col = "lightblue" # colore the bars )
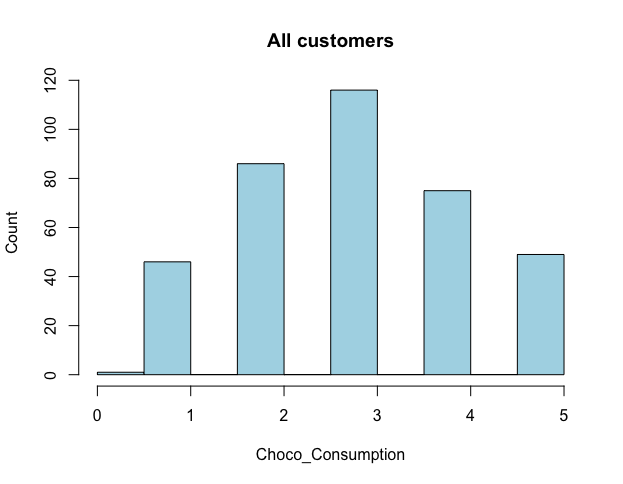
hist(seg.df$Choco_Consumption, main = "All customers", xlab = "Choco_Consumption", ylab = "Count", col = "lightblue" # colore the bars )
> head(seg.df, n = 5) Age_Group Gender Salary Education Location_by_region Choco_Consumption Sustainability_Score 352 1 2 1 2 3 0 -1.15059 103 3 2 3 1 1 1 0.50287 17 1 1 1 1 1 1 -1.14517 66 1 1 1 1 1 1 -0.46688 329 2 1 1 1 1 1 -2.08817 > summary(seg.df, digits = 2) Age_Group Gender Salary Education Location_by_region Choco_Consumption Min. :1.0 Min. :1.0 Min. :0.0 Min. :1.0 Min. :1.0 Min. :0 1st Qu.:1.0 1st Qu.:1.0 1st Qu.:1.0 1st Qu.:2.0 1st Qu.:1.0 1st Qu.:2 Median :2.0 Median :2.0 Median :2.0 Median :2.0 Median :1.0 Median :3 Mean :2.1 Mean :1.7 Mean :2.2 Mean :2.3 Mean :1.2 Mean :3 3rd Qu.:3.0 3rd Qu.:2.0 3rd Qu.:3.0 3rd Qu.:3.0 3rd Qu.:1.0 3rd Qu.:4 Max. :4.0 Max. :2.0 Max. :6.0 Max. :4.0 Max. :3.0 Max. :5 Sustainability_Score Min. :-3.3e+00 1st Qu.:-6.1e-01 Median : 1.4e-01 Mean :-9.6e-05 3rd Qu.: 6.8e-01 Max. : 2.0e+00 > str(seg.df) 'data.frame': 373 obs. of 7 variables: $ Age_Group : int 1 3 1 1 2 4 2 1 1 1 ... $ Gender : int 2 2 1 1 1 1 2 2 1 1 ... $ Salary : int 1 3 1 1 1 4 2 3 3 3 ... $ Education : int 2 1 1 1 1 1 1 2 2 2 ... $ Location_by_region : num 3 1 1 1 1 1 1 1 1 1 ... $ Choco_Consumption : int 0 1 1 1 1 1 1 1 1 1 ... $ Sustainability_Score: num -1.151 0.503 -1.145 -0.467 -2.088 ...
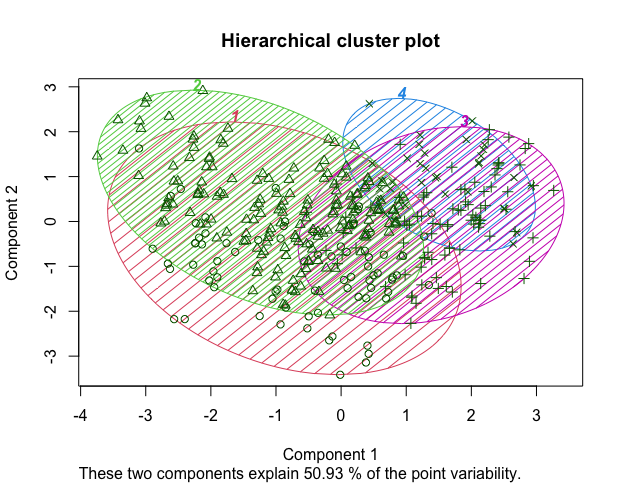
> clusplot(seg.df, seg.hc.segment, + color = TRUE, #color the groups + shade = TRUE, #shade the ellipses for group membership + labels = 4, #label only the groups, not the individual points + lines = 0, #omit distance lines between groups + main = "Hierarchical cluster plot" # figure title + )
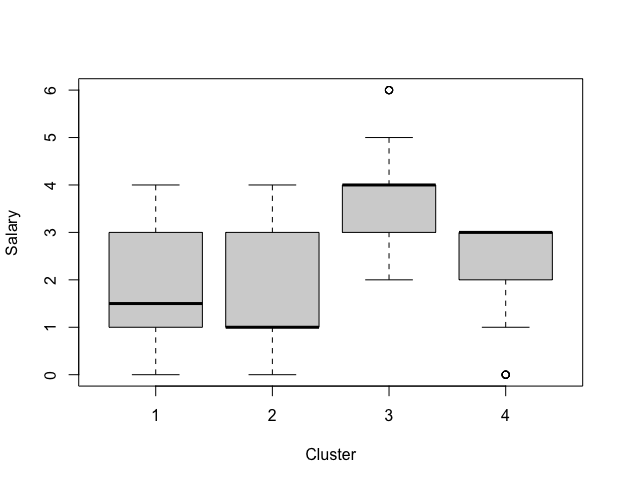
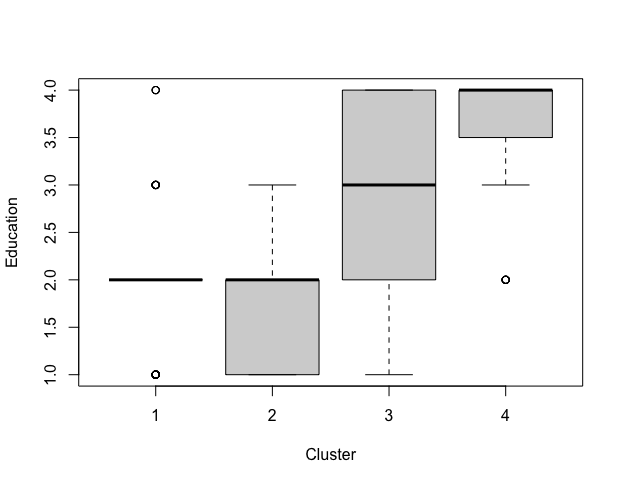
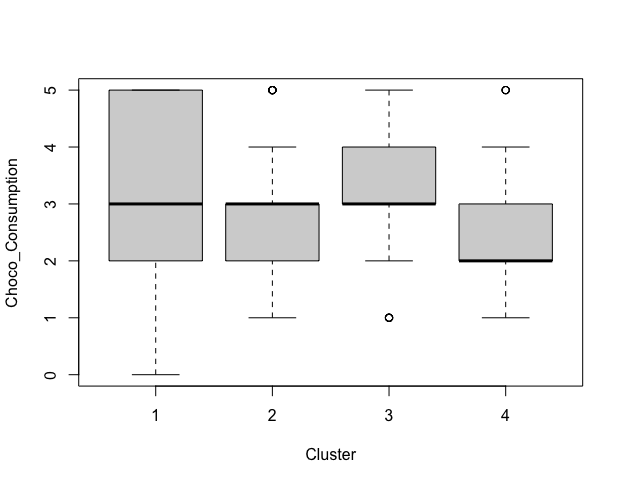
Graph split to 4 groups(Only explained 50.93% of the data), we see that group3 is modestly well-differentiated. 88 customers with higher salary and higher consumption of choco, means more potential to pay at a higher price. Second target is group4, higher educated rate and more sensitive to sustainability, companies can move towards sustainability and attract potential highly educated customers.
1.2 Factor analysis
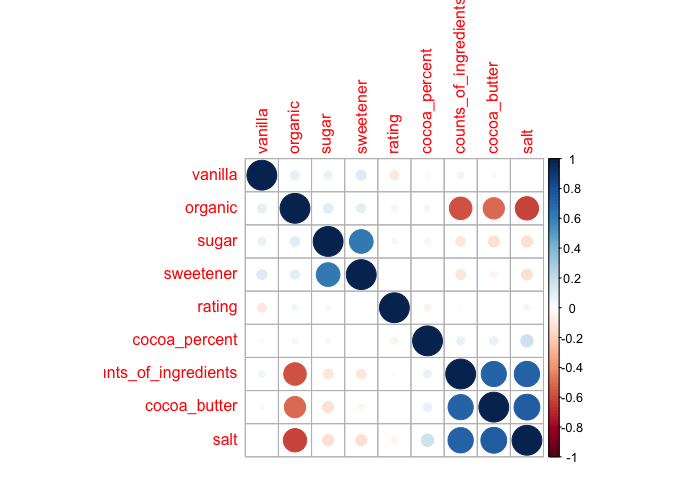
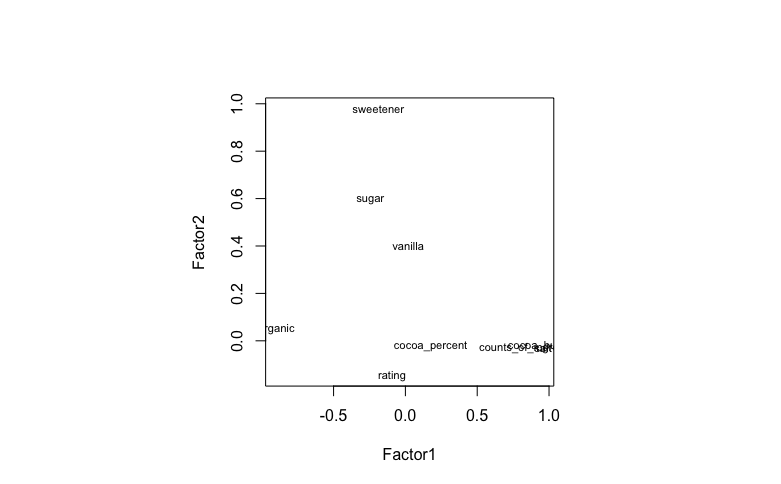
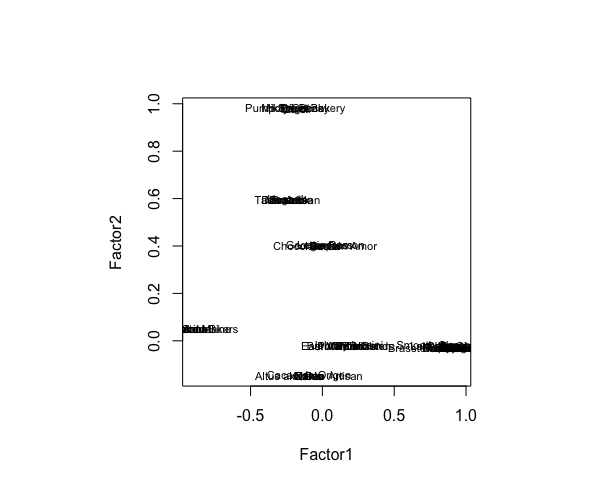
Remove unnecesssary columns from data: product_id,company_location,review_date,country_of_bean_origin,first_taste,second_taste,third_taste. Use heatmap and corrplot to visualizing the relation between factors. Finally using PCA find the position of brand, and looking for future brand positioning.
1.2.1 import and check data
> brand.ratings <- read.csv("2_chocolate_rating.csv", stringsAsFactors = TRUE) > > #### remove unnecessary columns > brand.ratings <- subset(brand.ratings, select = -c(product_id,company_location,review_date,country_of_bean_origin,first_taste,second_taste,third_taste)) > head(brand.ratings) brand cocoa_percent rating counts_of_ingredients cocoa_butter vanilla organic salt sugar sweetener 1 A. Morin 70 4.00 2 4 8 8 2 9 7 2 A. Morin 70 3.75 1 1 4 7 1 1 1 3 A. Morin 70 3.50 2 3 5 9 2 9 5 4 A. Morin 70 2.75 1 6 10 8 3 4 5 5 A. Morin 70 3.50 1 1 5 8 1 9 9 6 A. Morin 63 3.75 2 8 9 5 3 8 7 > summary(brand.ratings) brand cocoa_percent rating counts_of_ingredients cocoa_butter vanilla organic salt Soma : 11 Min. : 60.00 Min. :2.250 Min. : 1.000 Min. : 1.000 Min. : 1.000 Min. : 1.000 Min. : 1.000 Arete : 10 1st Qu.: 70.00 1st Qu.:3.000 1st Qu.: 2.000 1st Qu.: 3.000 1st Qu.: 6.000 1st Qu.: 3.000 1st Qu.: 2.000 Cacao de Origen : 10 Median : 70.00 Median :3.250 Median : 4.000 Median : 6.000 Median : 8.000 Median : 5.000 Median : 5.500 hexx : 8 Mean : 71.53 Mean :3.285 Mean : 5.078 Mean : 5.663 Mean : 7.407 Mean : 5.275 Mean : 5.384 Smooth Chocolator, The: 8 3rd Qu.: 74.00 3rd Qu.:3.500 3rd Qu.: 9.000 3rd Qu.: 8.000 3rd Qu.: 9.000 3rd Qu.: 8.000 3rd Qu.: 9.000 A. Morin : 7 Max. :100.00 Max. :4.000 Max. :10.000 Max. :10.000 Max. :10.000 Max. :10.000 Max. :10.000 (Other) :204 sugar sweetener Min. : 1.000 Min. : 1.000 1st Qu.: 2.000 1st Qu.: 3.000 Median : 4.000 Median : 4.000 Mean : 4.155 Mean : 4.415 3rd Qu.: 6.000 3rd Qu.: 6.000 Max. :10.000 Max. :10.000 > str(brand.ratings) 'data.frame': 258 obs. of 10 variables: $ brand : Factor w/ 56 levels "A. Morin","Altus aka Cao Artisan",..: 1 1 1 1 1 1 1 2 2 2 ... $ cocoa_percent : num 70 70 70 70 70 63 70 60 60 60 ... $ rating : num 4 3.75 3.5 2.75 3.5 3.75 3.5 3 2.75 2.5 ... $ counts_of_ingredients: int 2 1 2 1 1 2 1 2 2 3 ... $ cocoa_butter : int 4 1 3 6 1 8 1 1 1 1 ... $ vanilla : int 8 4 5 10 5 9 5 7 8 9 ... $ organic : int 8 7 9 8 8 5 7 5 10 8 ... $ salt : int 2 1 2 3 1 3 1 2 1 1 ... $ sugar : int 9 1 9 4 9 8 5 8 7 3 ... $ sweetener : int 7 1 5 5 9 7 1 7 7 3 ...
1.2.2 Rescaling the data
> brand.sc <- brand.ratings > brand.sc[,2:10] <- scale (brand.ratings[,2:10]) > head(brand.sc) brand cocoa_percent rating counts_of_ingredients cocoa_butter vanilla organic salt sugar sweetener 1 A. Morin -0.315311 1.8112654 -0.8883386 -0.5795367 0.2596824 0.96349072 -0.9958673 1.7971812 1.2538261 2 A. Morin -0.315311 1.1780588 -1.1769927 -1.6251343 -1.4919010 0.60989099 -1.2901786 -1.1703244 -1.6561032 3 A. Morin -0.315311 0.5448522 -0.8883386 -0.9280692 -1.0540051 1.31709044 -0.9958673 1.7971812 0.2838497 4 A. Morin -0.315311 -1.3547676 -1.1769927 0.1175284 1.1354741 0.96349072 -0.7015560 -0.0575098 0.2838497 5 A. Morin -0.315311 0.5448522 -1.1769927 -1.6251343 -1.0540051 0.96349072 -1.2901786 1.7971812 2.2238026 6 A. Morin -1.755138 1.1780588 -0.8883386 0.8145935 0.6975783 -0.09730845 -0.7015560 1.4262430 1.2538261 > summary(brand.sc) brand cocoa_percent rating counts_of_ingredients cocoa_butter vanilla organic Soma : 11 Min. :-2.3722 Min. :-2.62118 Min. :-1.1770 Min. :-1.6251 Min. :-2.8056 Min. :-1.51171 Arete : 10 1st Qu.:-0.3153 1st Qu.:-0.72156 1st Qu.:-0.8883 1st Qu.:-0.9281 1st Qu.:-0.6161 1st Qu.:-0.80451 Cacao de Origen : 10 Median :-0.3153 Median :-0.08835 Median :-0.3110 Median : 0.1175 Median : 0.2597 Median :-0.09731 hexx : 8 Mean : 0.0000 Mean : 0.00000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.00000 Smooth Chocolator, The: 8 3rd Qu.: 0.5074 3rd Qu.: 0.54485 3rd Qu.: 1.1322 3rd Qu.: 0.8146 3rd Qu.: 0.6976 3rd Qu.: 0.96349 A. Morin : 7 Max. : 5.8554 Max. : 1.81127 Max. : 1.4209 Max. : 1.5117 Max. : 1.1355 Max. : 1.67069 (Other) :204 salt sugar sweetener Min. :-1.29018 Min. :-1.17032 Min. :-1.6561 1st Qu.:-0.99587 1st Qu.:-0.79939 1st Qu.:-0.6861 Median : 0.03422 Median :-0.05751 Median :-0.2011 Mean : 0.00000 Mean : 0.00000 Mean : 0.0000 3rd Qu.: 1.06431 3rd Qu.: 0.68437 3rd Qu.: 0.7688 Max. : 1.35862 Max. : 2.16812 Max. : 2.7088 > str(brand.sc) 'data.frame': 258 obs. of 10 variables: $ brand : Factor w/ 56 levels "A. Morin","Altus aka Cao Artisan",..: 1 1 1 1 1 1 1 2 2 2 ... $ cocoa_percent : num -0.315 -0.315 -0.315 -0.315 -0.315 ... $ rating : num 1.811 1.178 0.545 -1.355 0.545 ... $ counts_of_ingredients: num -0.888 -1.177 -0.888 -1.177 -1.177 ... $ cocoa_butter : num -0.58 -1.625 -0.928 0.118 -1.625 ... $ vanilla : num 0.26 -1.49 -1.05 1.14 -1.05 ... $ organic : num 0.963 0.61 1.317 0.963 0.963 ... $ salt : num -0.996 -1.29 -0.996 -0.702 -1.29 ... $ sugar : num 1.7972 -1.1703 1.7972 -0.0575 1.7972 ... $ sweetener : num 1.254 -1.656 0.284 0.284 2.224 ...
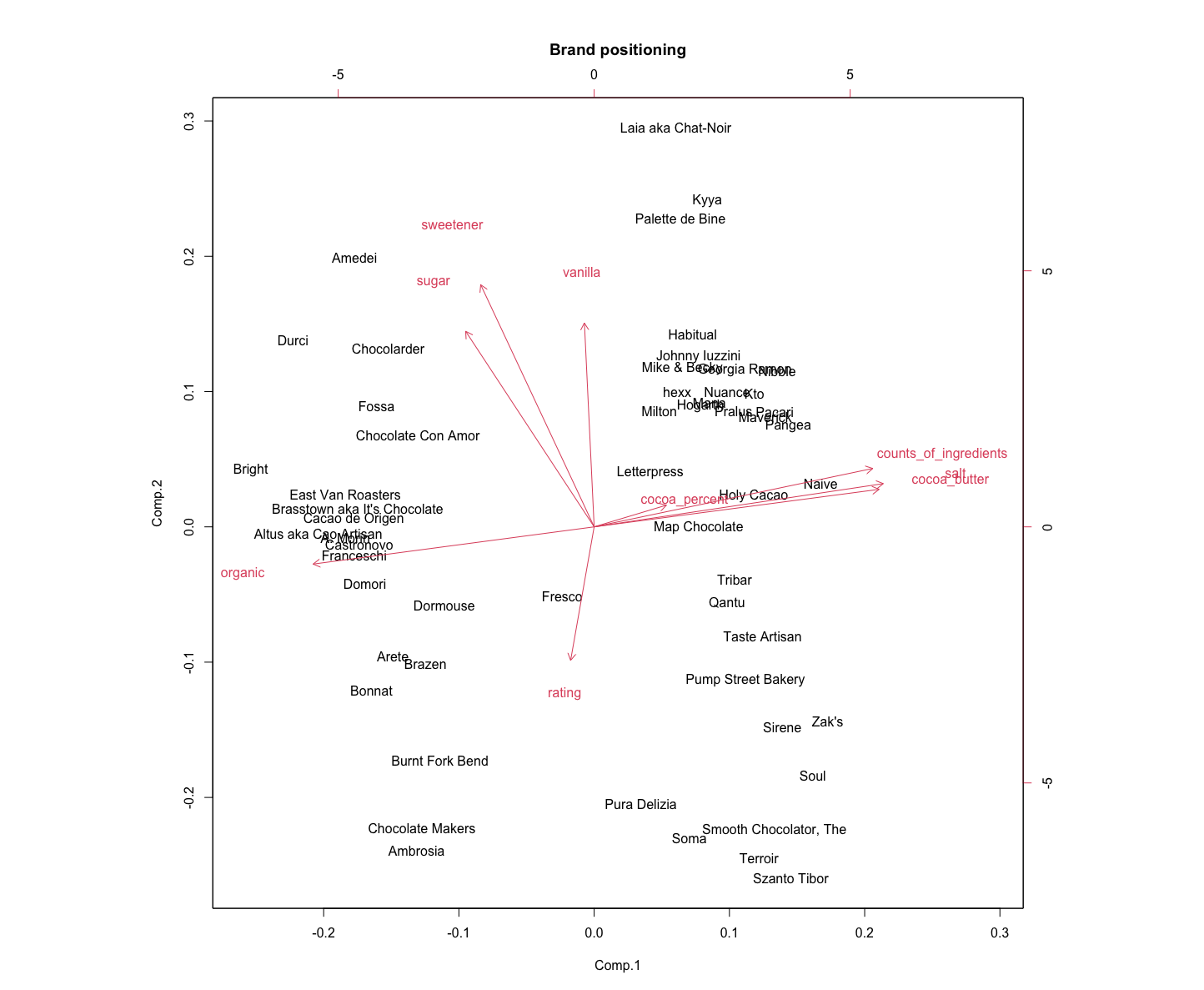
If the brand wants to enhance its differentiation from other brands, brand can focus on balancing the organic and rating aspects. This is more in line with the sustainable development mentioned earlier, and there are fewer brands in this position.
And then, we can use brand.mean or colMeans to calculate the difference distance to target brand.
1.2.5 move forward
Suppose we already have the basis for organic, such as brand Casttronovo. If we want to move forward rating, such as brand Fresco, we should increasing its emphasis on salt, counts_of_ingredients and cocoa_butter. And decrease organic and sweetener.
> head(cbc.df, n = 5) Consumer_id Block Choice_id Alternative Choice Origin Manufacture Energy Nuts Tokens Organic Premium Fairtrade Sugar Price 1 1 1 1 1 1 Venezuela Developed Low Nuts only No No Yes Yes High 3 2 1 1 1 2 0 Venezuela UnderDeveloped Low Nuts only Keep & Use No No Yes Low 5 3 1 1 1 3 0 Peru Developing High No Donate Yes No No High 7 4 1 1 2 1 0 Ecuador UnderDeveloped Low Nuts and Fruit Donate Yes No No High 3 5 1 1 2 2 0 Venezuela Developed Low No No No Yes Yes Low 3 Age_Group Gender Salary Education Employment Location_by_region Choco_Consumption Sustainability_Score 1 1 2 1 2 1 1 2 -0.6645 2 1 2 1 2 1 1 2 -0.6645 3 1 2 1 2 1 1 2 -0.6645 4 1 2 1 2 1 1 2 -0.6645 5 1 2 1 2 1 1 2 -0.6645
> summary(cbc.df, digits = 2) Consumer_id Block Choice_id Alternative Choice Origin Manufacture Energy Nuts Min. : 1 Min. :1.0 Min. : 1 Min. :1 Min. :0.00 Ecuador :1902 Developed :1418 High:2356 No :2317 1st Qu.: 95 1st Qu.:3.0 1st Qu.: 473 1st Qu.:1 1st Qu.:0.00 Peru :1506 Developing :2311 Low :3314 Nuts and Fruit:1420 Median :190 Median :4.0 Median : 946 Median :2 Median :0.00 Venezuela:2262 UnderDeveloped:1941 Nuts only :1933 Mean :190 Mean :4.5 Mean : 946 Mean :2 Mean :0.33 3rd Qu.:284 3rd Qu.:6.0 3rd Qu.:1418 3rd Qu.:3 3rd Qu.:1.00 Max. :378 Max. :8.0 Max. :1890 Max. :3 Max. :1.00 Tokens Organic Premium Fairtrade Sugar Price Age_Group Gender Salary Education Employment Donate :1418 No :2664 No :2652 No :2646 High:2670 Min. :2.0 Min. :1.0 Min. :0.0 Min. :0.0 Min. :1.0 Min. : 1.0 Keep & Use:1945 Yes:3006 Yes:3018 Yes:3024 Low :3000 1st Qu.:3.0 1st Qu.:1.0 1st Qu.:1.0 1st Qu.:1.0 1st Qu.:2.0 1st Qu.: 1.0 No :2307 Median :4.0 Median :1.0 Median :2.0 Median :2.0 Median :2.0 Median : 2.0 Mean :4.5 Mean :1.5 Mean :1.6 Mean :2.3 Mean :1.8 Mean : 2.4 3rd Qu.:5.0 3rd Qu.:2.0 3rd Qu.:2.0 3rd Qu.:3.0 3rd Qu.:2.0 3rd Qu.: 3.0 Max. :7.0 Max. :2.0 Max. :2.0 Max. :7.0 Max. :2.0 Max. :10.0 Location_by_region Choco_Consumption Sustainability_Score Min. :1.0 Min. :1 Min. :-3.26 1st Qu.:1.0 1st Qu.:2 1st Qu.:-0.61 Median :1.0 Median :2 Median : 0.14 Mean :1.2 Mean :2 Mean : 0.00 3rd Qu.:1.0 3rd Qu.:2 3rd Qu.: 0.68 Max. :2.0 Max. :2 Max. : 2.04
Demonstrated that positive value of utility means prefer than reference value, meanwhile negative value indicates that they prefer reference level.
In case of the Nuts attribute, customers prefer more nuts, etc.
2.1.4 Model fit
> model.constraint <-mlogit(Choice ~ 0+Nuts, data = cbc.mlogit) > lrtest(model, model.constraint) Likelihood ratio test
If the predictions were random, the accuracy would be 33.3% (for three alternatives). Our simple model is doing much better than that – although it is not perfect.
2.2 Willingness to pay
2.2.1 What is the Nuts’ value
> (coef(model)["NutsNuts and Fruit"]-coef(model)["NutsNuts only"]) / (-coef(model)["Price"]) NutsNuts and Fruit 0.9784127
The dollar value of an upgrade from Nuts only to Nuts and Fruit.
2.2.2 Willingness to Pay for an Attribute Upgrade
> coef(model)["NutsNuts and Fruit"] / (-coef(model)["Price"]) NutsNuts and Fruit 4.167859
The dollar value of an upgrade from No Nuts to Nuts and Fruit (No Nuts is reference level. Hence its coeff is 0)
> retail.trans <- as(retail.list, "transactions") #takes a few seconds Warning message: In asMethod(object) : removing duplicated items in transactions > summary(retail.trans) transactions as itemMatrix in sparse format with 9835 rows (elements/itemsets/transactions) and 324 columns (items) and a density of 0.01357711
most frequent items: whole milk milk chocolate bread soda yogurt (Other) 1796 1782 1473 1421 1147 35645
Min. 1st Qu. Median Mean 3rd Qu. Max. 1.000 2.000 3.000 4.399 6.000 32.000
includes extended item information - examples: labels 1 abrasive cleaner 2 artif. sweetener 3 baby cosmetics
includes extended transaction information - examples: transactionID 1 Trans 1 2 Trans 2 3 Trans 3
Looking at the summary() of the resulting object, we see that the transaction-by-item matrix is 9,835 rows by 324 columns. Of those 3.1 million intersections, only 1% have positive data (density) because most items are not purchased in most transactions. Item whole milk appears the most frequently and occurs in 1,796 baskets of all transactions. 2,159 of the transactions contain only a single item (“sizes” = 1) and the median basket size is 3 items.
2.3.2 Retail Transaction Data: Groceries
We now use apriori(data, parameters = …) to find association rules with the apriori algorithm. At a conceptual level, the apriori algorithm searches through the item sets that frequently occur in a list of transactions. For each item set, it evaluates the various possible rules that express associations among the items at or above a particular level of support, and then retains the rules that show confidence above some threshold value.
To control the extent that apriori() searches, we use the parameter=list() control to instruct the algorithm to search rules that have a minimum support of 0.01 (1% transactions) and extract the ones that further demonstrate a minimum confidence of 0.3. The resulting rules set is assigned to the groc.rules object:
“sorting and recoding items … [97 item(s)] done [0.00s].”: tells us that the rules found are using 97 of the total number of items. If this number is too small (only a tiny set of your items) or too large (almost all of them), then you might wish to adjust the support and confidence levels.
“writing … [118 rule(s)] done [0.00s].”: Next, check the number of rules found, as indicated on the “writing …” line. In this case, the algorithm found 118 rules. If this number is too low, it suggests the need to lower the support or confidence levels; if it is too high (such as many more rules than items), you might increase the support or confidence levels.
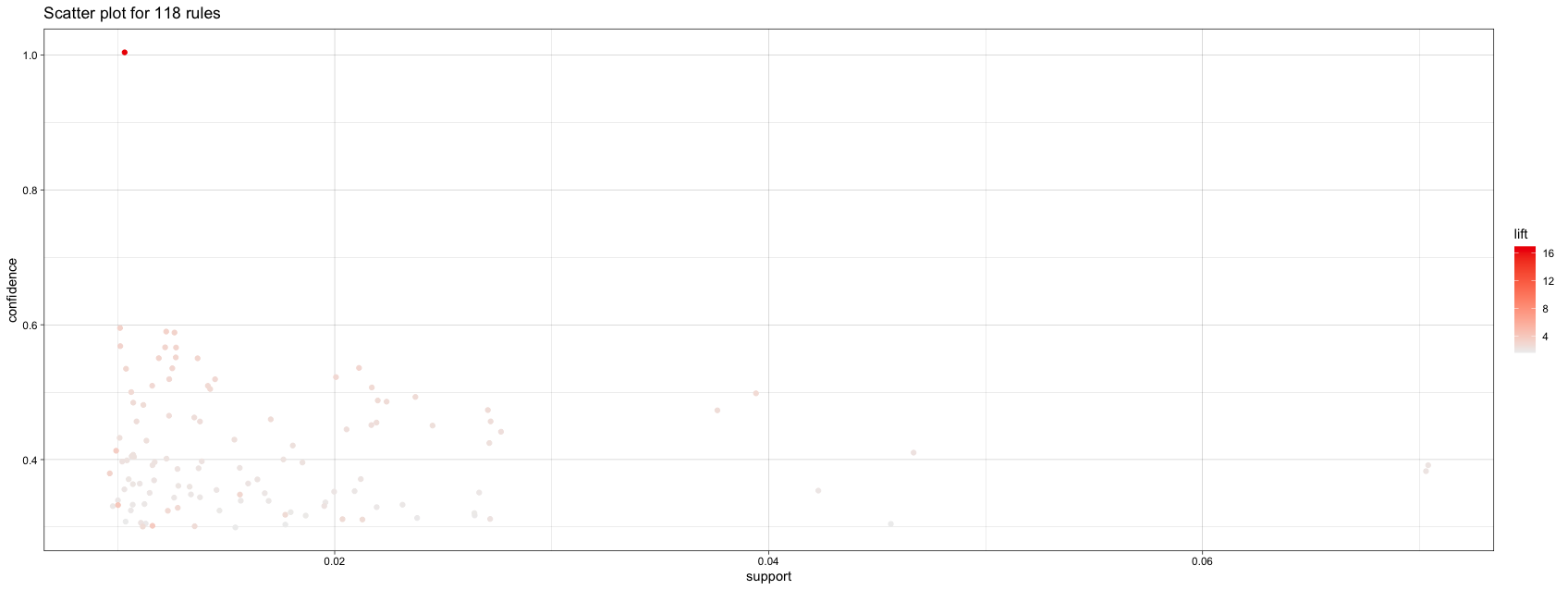
Once we have a rule set from apriori(), we use inspect(rules) to examine the association rules. The complete list of 118 from above is too long to examine here, so we select a subset of them with high lift, lift > 3. We find that five of the rules in our set have lift greater than 3.0:
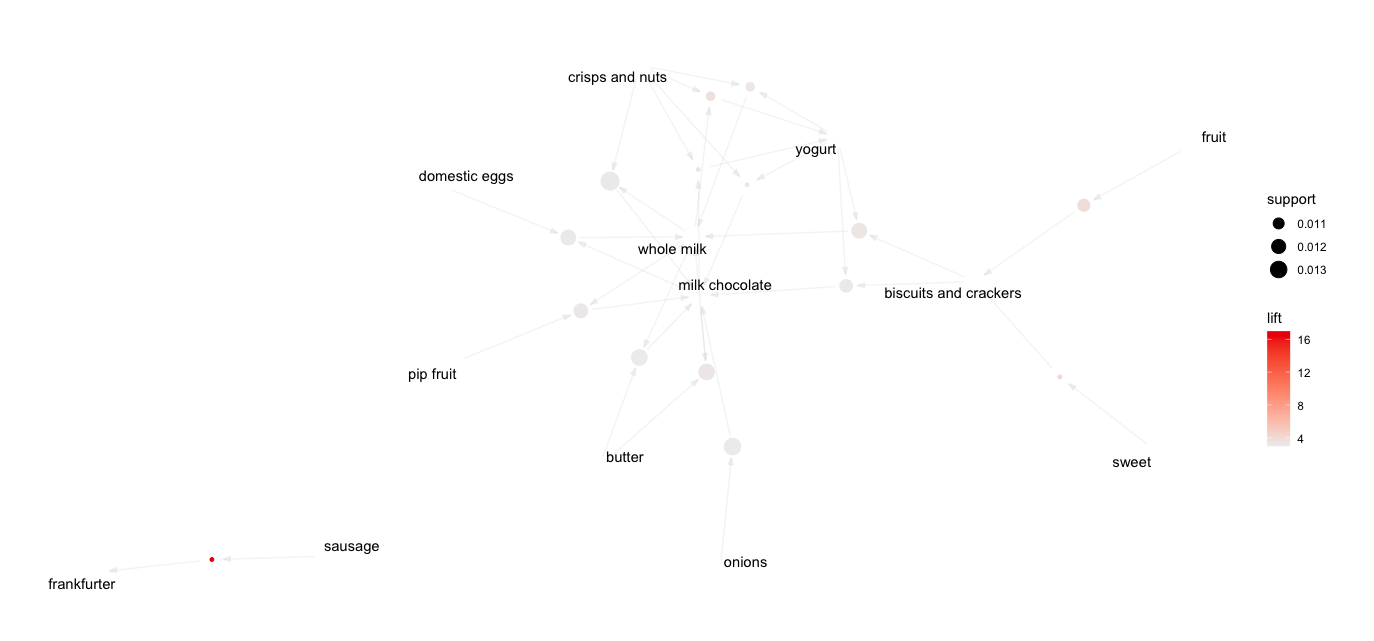
The first rule tells us that if a transaction contains {sausage} then it is also relatively more likely to contain {frankfurter}. The support shows that the combination appears in 1% of baskets, and the lift shows that the combination is 17× more likely to occur together than one would expect from the individual rates of incidence alone.
A store might form several insights on the basis of such information. For instance, the store might create a display for frankfurter near the sausage to encourage shoppers who are examining sausage to purchase those frankfurter with them. It might also suggest putting coupons for frankfurter in the sausage area or featuring recipe cards somewhere in the store.
plot(groc.rules)
In that chart, we see that most rules involve item combinations that infrequently occur (that is, they have low support) while confidence is relatively smoothly distributed.
Simply showing points is not very useful, and a key feature with arulesViz is interactive plotting. In the above figure, there are some rules on the upper left with a high lift. We can use interactive plotting to inspect those rules. To do this, add interactive=TRUE to the plot() command:
One rule tells us that the combination {crisps and nuts, yogurt} occurs in about 1.0 % of baskets (support=0.0105), and when it occurs, it highly likely includes {whole milk} (confidence= 0.595). The combination occurs 3 times more often than we would expect from the individual incidence rates of {crisps and nuts, yogurt} and {whole milk} considered separately (lift=3.26).
A common goal in market basket analysis is to find rules with high lift. We can find such rules easily by sorting the larger set of rules by lift. We extract the 15 rules with the highest lift using sort() to order the rules by lift and to take 50 from the head():
Support and lift are identical for an item set regardless of the items’ order within a rule (left-hand or right-
hand side of the rule). However, confidence reflects direction because it computes the occurrence of the right-hand set conditional on the left-hand side set.
A graph display of rules may be useful to seek themes and patterns at a higher level. We chart the top 15 rules byliftwithplot(… ,method=“graph”):
The positioning of items on the resulting graph may differ for your system, but the item clusters should be similar. Each circle represents a rule, with inbound arrows coming from items on the left-hand side of
the rule and outbound arrows going to the right-hand side. The size (area) of the circle represents the rule’s support, and shade represents lift (darker indicates higher lift).
Residual standard error: 214.3 on 193 degrees of freedom Multiple R-squared: 0.8365, Adjusted R-squared: 0.8314 F-statistic: 164.5 on 6 and 193 DF, p-value: < 2.2e-16
3.1.2.2 log
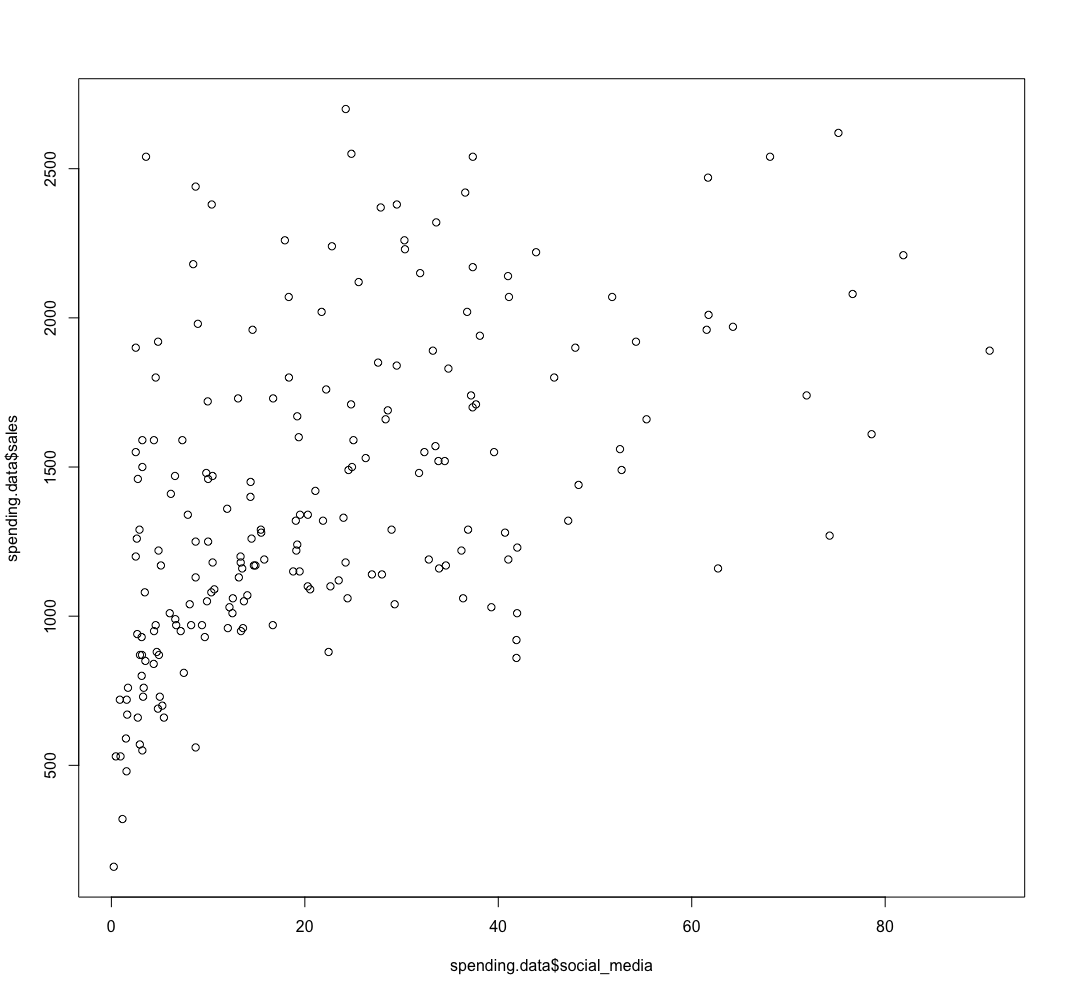
> ## log > summary(spending.data$radio) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.04 9.30 22.00 23.23 36.35 79.60 > summary(spending.data$magazines) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.030 1.050 3.420 4.828 6.383 61.160 > summary(spending.data$social_media) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.245 7.050 18.137 22.289 33.523 90.800 > summary(spending.data$search_ads) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.1568 5.6442 11.6133 14.2485 21.4547 50.3014 > summary(spending.data$tv) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.70 74.38 149.75 147.04 218.82 296.40 > summary(spending.data$newspaper) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.30 12.75 25.75 30.55 45.10 114.00 > > regression_2 <- lm(log(sales) ~ log(radio) + log(magazines) + log(social_media) + log(search_ads) + log(tv) + log(newspaper), data=spending.data) > # 90.15% explained > summary(regression_2)
Residual standard error: 0.13 on 193 degrees of freedom Multiple R-squared: 0.9045, Adjusted R-squared: 0.9015 F-statistic: 304.7 on 6 and 193 DF, p-value: < 2.2e-16
Residual standard error: 0.1315 on 197 degrees of freedom Multiple R-squared: 0.9003, Adjusted R-squared: 0.8993 F-statistic: 889.6 on 2 and 197 DF, p-value: < 2.2e-16
3.1.3 Allocating Marketing Budget
Sum elasticity
0.49 = 0.14 + 0.35
Ratio of elasticity
0.2857 = 0.14 / 0.49
TV of elasticity
0.7143 = 0.35 / 0.49
Obtain elasticities from model
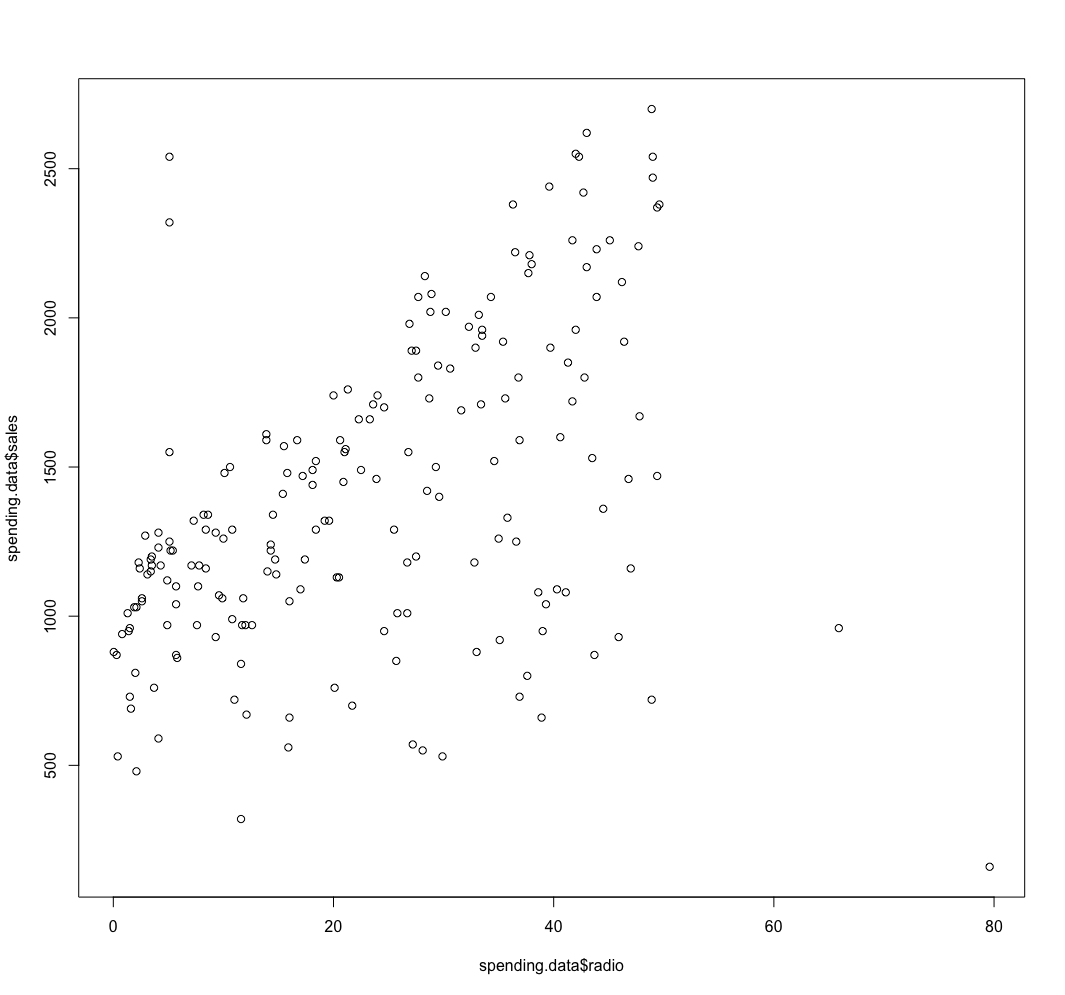
> mean(spending.data$radio) [1] 23.2297 > mean(spending.data$tv) [1] 147.0425 > mean(spending.data$sales) [1] 1402.25 > > # radio > # A 1% increase in radio advertising results in a 0.26% increase in sales. > 0.143520 * (23.2297 / 1402.25) [1] 0.002377555 > > # tv > # A 1% increase in tv advertising results in a 0.26% increase in sales. > 0.364471 * (147.0425 / 1402.25) [1] 0.0382191
3.1.4 Advertising Carryover Effect
We are assumed to retain a 10% of your previous advertising stock.
Residual standard error: 0.1566 on 193 degrees of freedom Multiple R-squared: 0.8615, Adjusted R-squared: 0.8572 F-statistic: 200 on 6 and 193 DF, p-value: < 2.2e-16
Residual standard error: 0.157 on 197 degrees of freedom Multiple R-squared: 0.858, Adjusted R-squared: 0.8565 F-statistic: 594.9 on 2 and 197 DF, p-value: < 2.2e-16
Residual standard error: 0.1116 on 192 degrees of freedom Multiple R-squared: 0.93, Adjusted R-squared: 0.9274 F-statistic: 364.2 on 7 and 192 DF, p-value: < 2.2e-16
Residual standard error: 0.1142 on 196 degrees of freedom Multiple R-squared: 0.9252, Adjusted R-squared: 0.9241 F-statistic: 808.3 on 3 and 196 DF, p-value: < 2.2e-16
Residual standard error: 0.1116 on 192 degrees of freedom Multiple R-squared: 0.93, Adjusted R-squared: 0.9274 F-statistic: 364.2 on 7 and 192 DF, p-value: < 2.2e-16
Residual standard error: 0.1142 on 196 degrees of freedom Multiple R-squared: 0.9252, Adjusted R-squared: 0.9241 F-statistic: 808.3 on 3 and 196 DF, p-value: < 2.2e-16
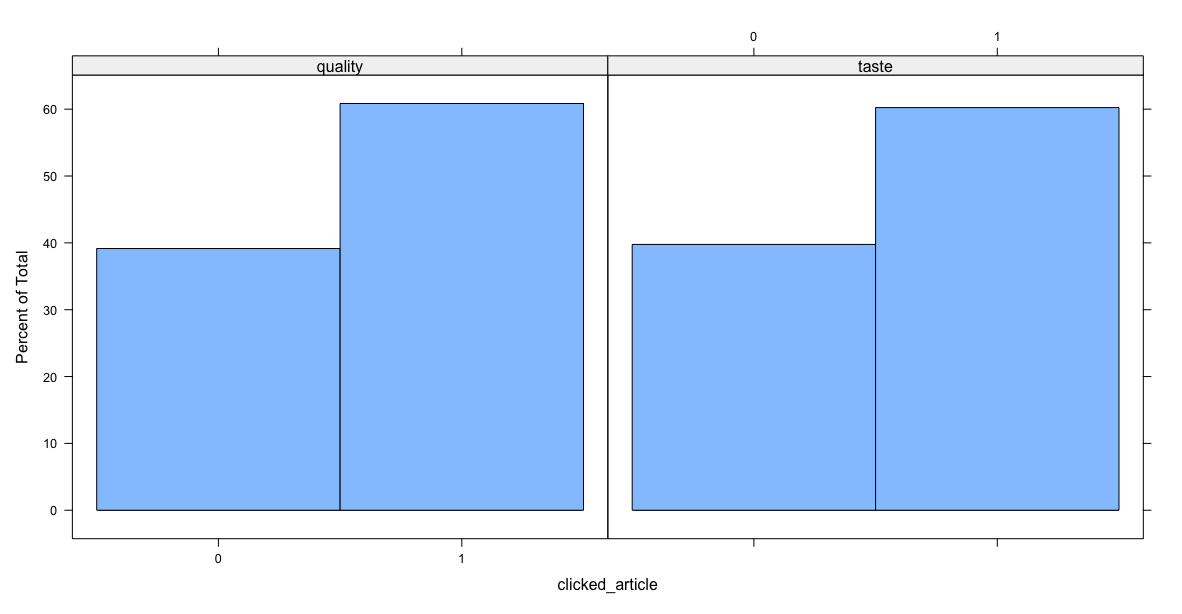
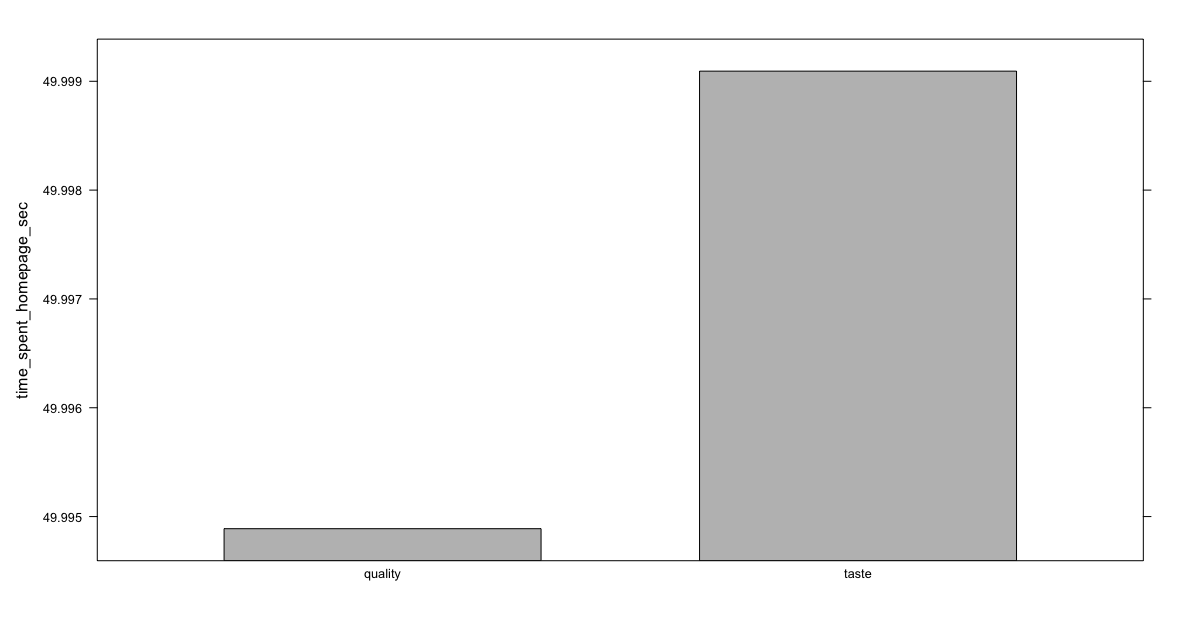
> # t.test() > t.test(time_spent_homepage_sec ~ condition, data = ad.df)
Welch Two Sample t-test
data: time_spent_homepage_sec by condition t = -0.36288, df = 29997, p-value = 0.7167 alternative hypothesis: true difference in means between group quality and group taste is not equal to 0 95 percent confidence interval: -0.02691480 0.01850573 sample estimates: mean in group quality mean in group taste 49.99489 49.99909
3.2.4.3 anova
> ad.aov.con <- aov(time_spent_homepage_sec ~ condition, data = ad.df) > anova(ad.aov.con) Analysis of Variance Table
Response: time_spent_homepage_sec Df Sum Sq Mean Sq F value Pr(>F) condition 1 0.1 0.13259 0.1317 0.7167 Residuals 29998 30204.2 1.00687