一、背景
手机原生通话应用,实现流式语音翻译。
二、差异
和以往客户接入不同,需要我们自行监听RTP流(通过SDP描述文件),并且终端输入的音频流并非我们可接受的WAV/PCM格式,而是AMR-WB,需要我们监听RTP流获取音频数据。终端通信设备是现网设备,编码方式无法变更,需要我们来实现音频数据的解码。
初版实现

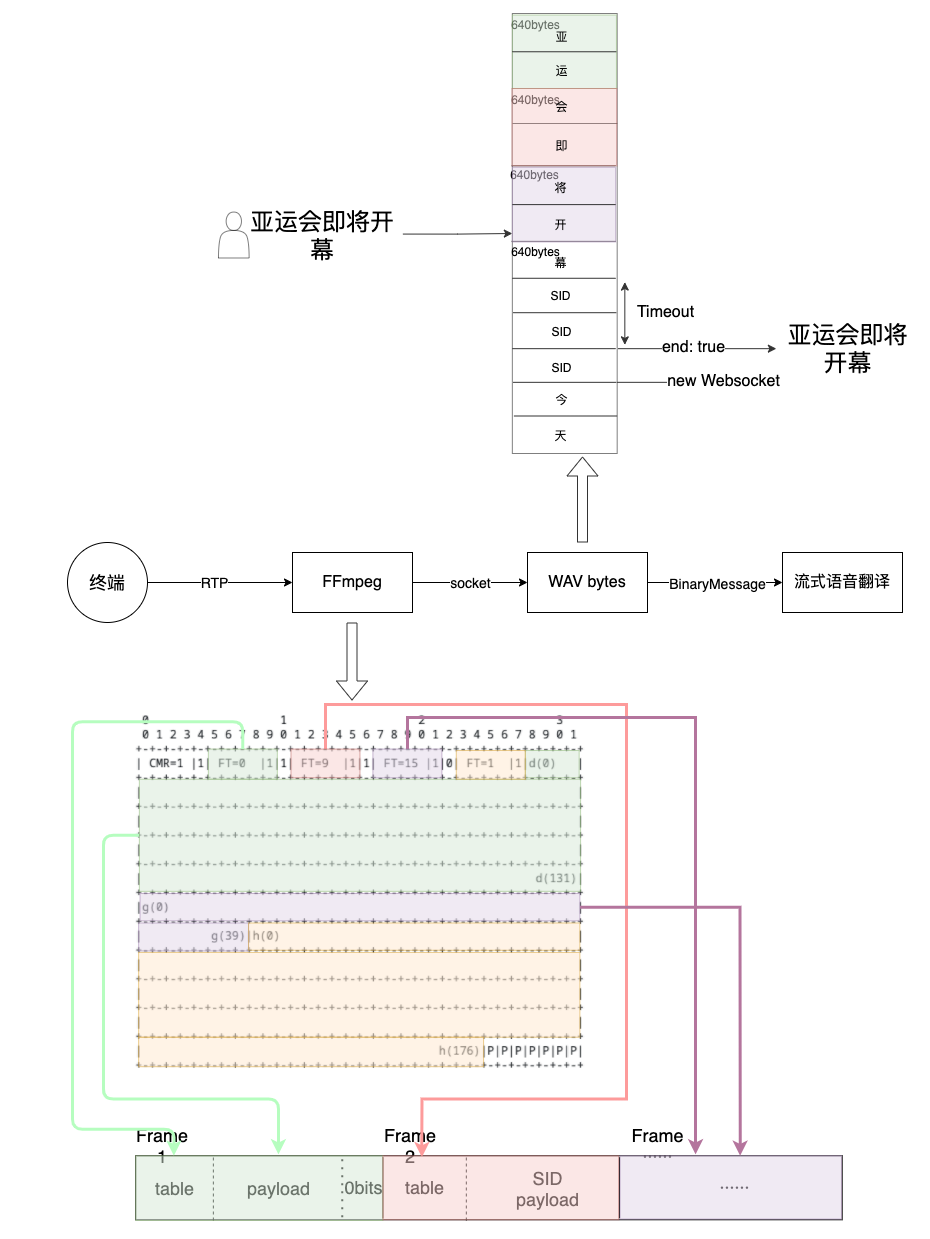
借助FFmpeg输入SDP监听对应地址的RTP,并根据SDP中描述的音频编码进行解码以及转格式,直接输出到WAV文件中。Java程序读取WAV文件,做ASR+翻译。
三、预期外的困难与解决方式
1. AMR-WB编码音频,FFmpeg不能完全支持解码
AMR-WB编码分为两种,Bandwidth-efficient 和 Octet-aligned。
阅读RFC 4867协议后,发现bandwidth-efficient和octet-aligned之间的差距并不大,内容不变,只是排除了中间的填充字节,更紧凑了些:
bandwidth efficient
header:
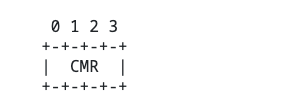
table:
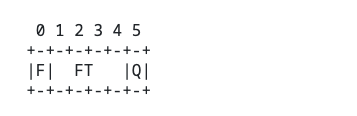
payload:

octet aligned
header:
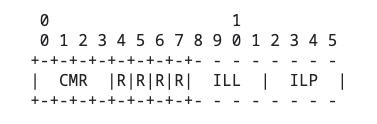
table:

payload:

终端所采用的AMR-WB并非常见的Octet-aligned,而是Bandwidth-efficient。不幸,FFmpeg并不支持这种模式的编码:rtpdec_amr.c
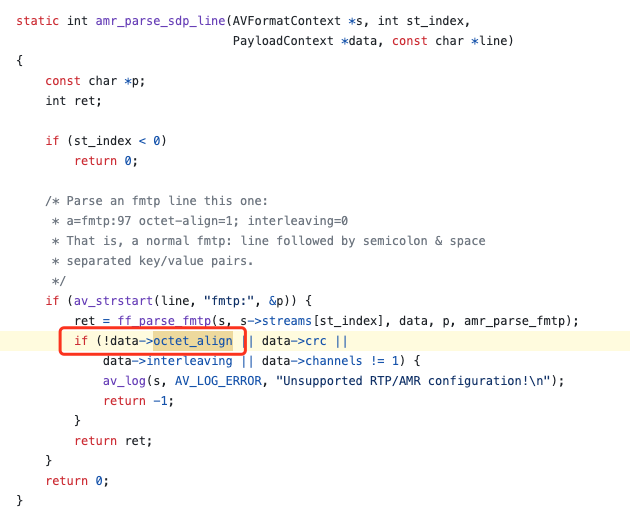
方案1: python(RTP解码+重编码) -> ffmpeg转格式 -> ASR
运维帮忙找到了一个脚本,可以实现AMR-WB Bandwidth-efficient音频的解码,并提取出其中有效的payload,输出到文件中。最终生成的文件可以通过ffmpeg进一步转格式,得到可接受的WAV。基于这个脚本,运维开发了一个简单的解码器,针对于这种格式,监听RTP流并转码。

但是,这种方式会带来新的问题:
- 如果终端的数据不是AMR格式,不适用于这条路,还需要走老流程,所以对于音频处理会分成两条路:
如果在通信过程中发生音频编码的变化(SDP信息更新),Java服务需要在两条路之间来回切换,增加了稳定性风险和复杂度。所以在有了保底方案之后,继续尝试另一种方式。
方案2: 修改ffmpeg,支持AMR Bandwidth-efficient编码
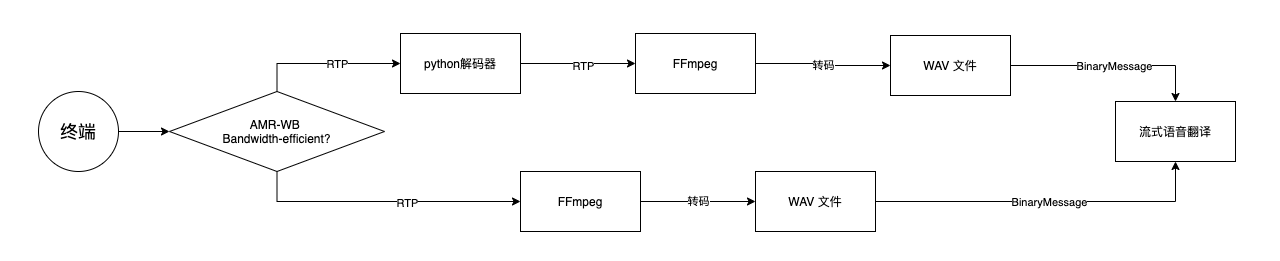
1.简单分析一下FFmpeg对amr的解码部分,对于octet-aligned模式,实际上就是按照字节读取,逐帧剥离数据,送到后面的decoder:

最终送去转码的audio-data结构:

那么对于bandwidth-efficient,payload一致的前提下,我们只需要重写解析逻辑,按位读取,并在适当的位置填充0bit,即可转化成octet-aligned模式的数据,继续后面的解码:
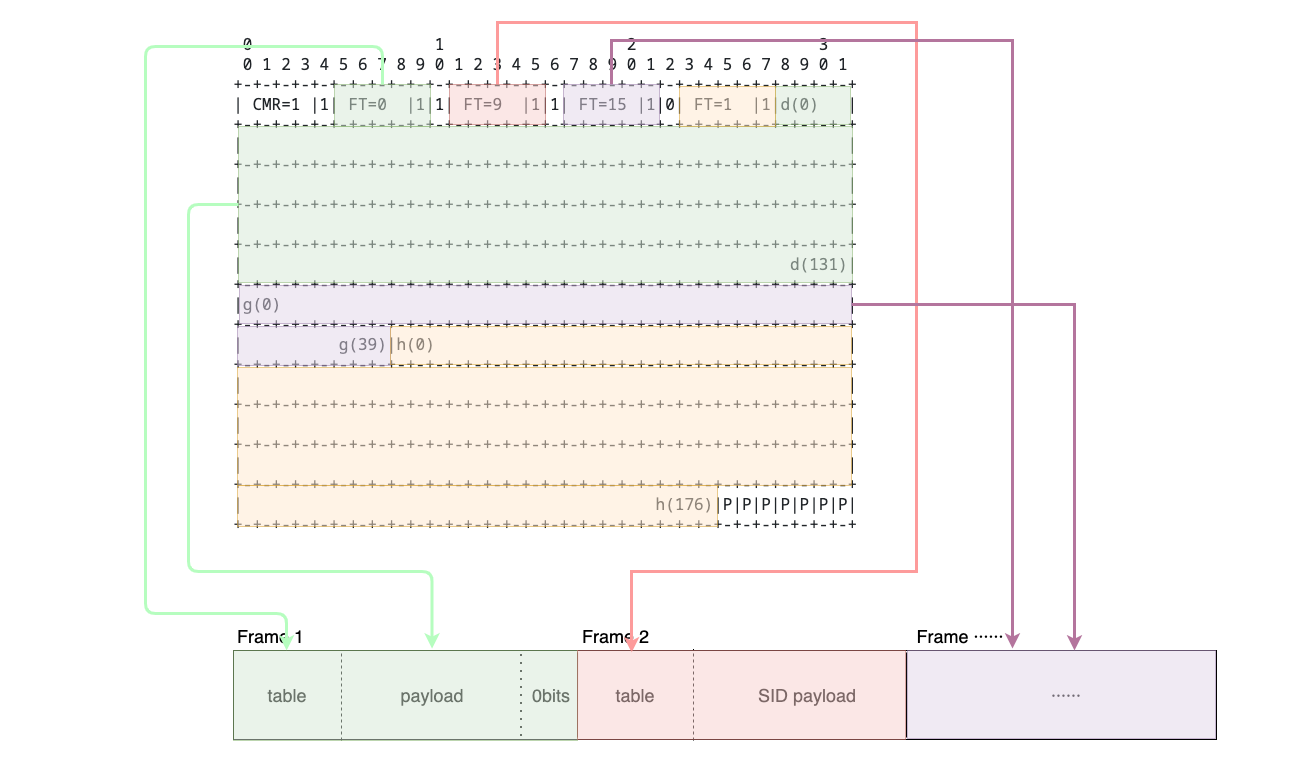
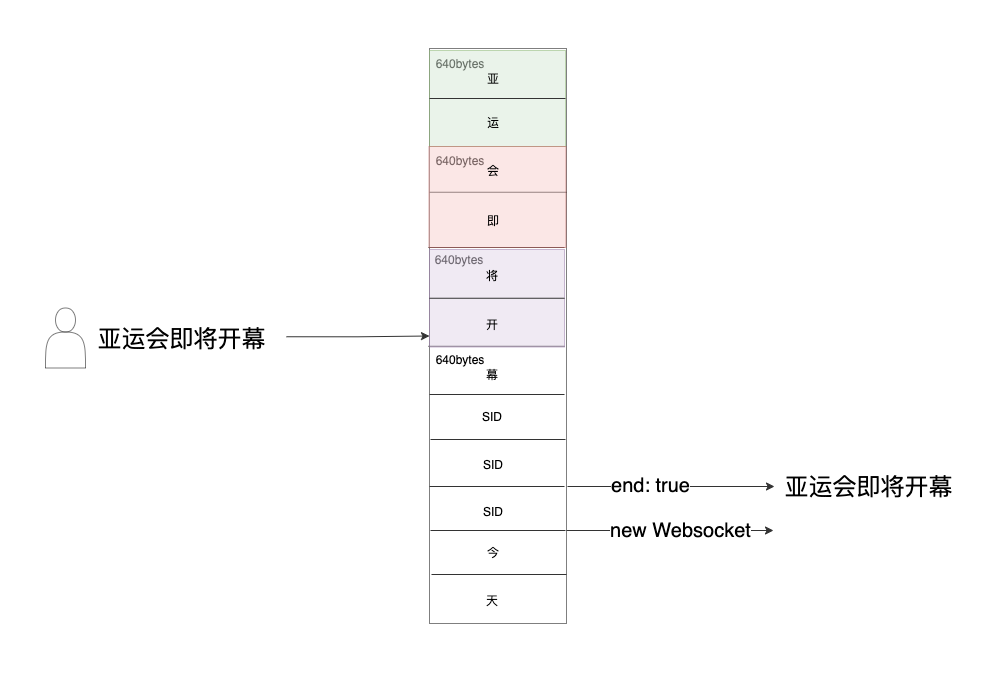
2. 静音期间,解码器不工作

当碰到SID的时候,AMR-decoder不会对音频数据进行解码,而是选择“忽略”。造成在静音的一段时间内,服务无法收到解码后的数据,也就无法向ASR发送音频数据。而ASR无法收到足够的音频,也无法进行识别,从终端体验来看,像是一句话的最后几个字“被吞了”,直到开始说下一句话才继续识别:
方案1: 让FFmpeg支持SID解码时填充静音数据
难度大,否
方案2: 让ASR支持客户端主动发起断句,断句后继续维持websocket识别
算法改动麻烦,否
方案3: NIO异步从socket读取数据,加设超时时间
在静音时段内,将无法收到bytes,一旦触发超时,客户端主动断开websocket,触发ASR断句,然后再重新建立新的链接
四、最终实现