<On the Duality of Operating System Structures> 1. The two models are duals of each other. That is, a program or subsystem constructed strictly according to the primitives defined by one model can be mapped directly into a dual program or subsystem which fits the other model. 2. The dual programs or subsystems are logically identical to each other. They can also be made textually very similar, differing only in non-essential details. 3. The performance of a program or subsystem from one model, as reflected by its queue lengths, waiting times, service rates, etc. is identical to that of its dual system, given identical scheduling strategies. Furthermore, the primitive operations provided by the operating system of one model can be made as efficient as their duals of the other model.
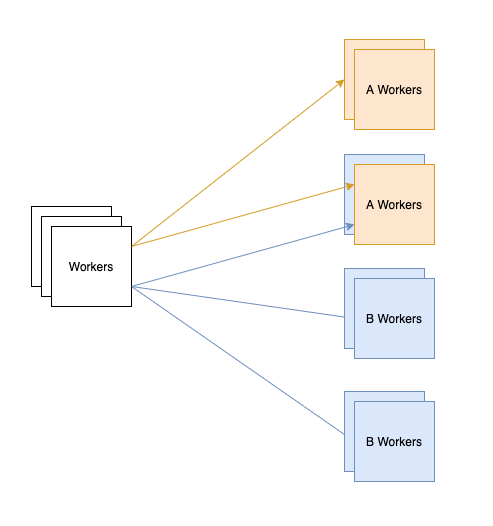
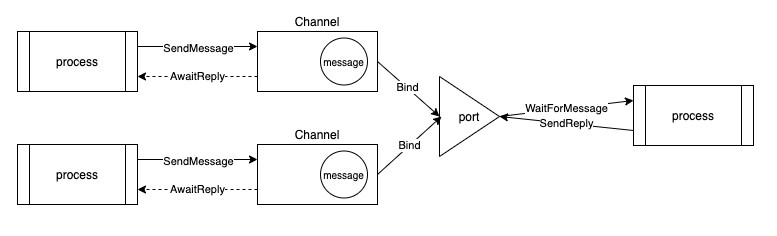
Messages and message identifiers. A message is a data structure meant for sending information from one process to another; it typically contains a small, fixed area for data which is passed by value and space for a pointer to larger data structures which must be passed by reference. A message identifier is a handle by which a particular message can be identified. Message channels and message ports. A message channel is an abstract structure which identifies the destination of a message. A message port is queue capable of holding messages of a certain class or type which might be received by a particular process. Each message channel must be bound to a particular message port before is can be used. A message port, however, may have more than one message channel bound to it. Four message transmission operations: 1. SendMessage[messageChannel, messageBody] returns [messageId] This operation simply queues a new message on the port bound to the the messageChannel named as parameter. The messageld returned is used as parameter to the following operation. 2. AwaitReply(messageId] returns [messageBody] The operation causes the process to wait for a reply to a specific message previously sent via SendMessage. 3. WaitForMessage[set of messagePort] returns [messageBody, messageld, messagePort] This operation allows a process to wait for a new (unsolicited) message on any one of the message ports named in the 'parameter. The message which is first on the queue is returned, along with a message identifier for future reference and an indication of the port from which that message came. 4. SendReply[messageId, messageBody] This operation sends a reply to the particular message identified by the message identifier.
SKIP FIGURE
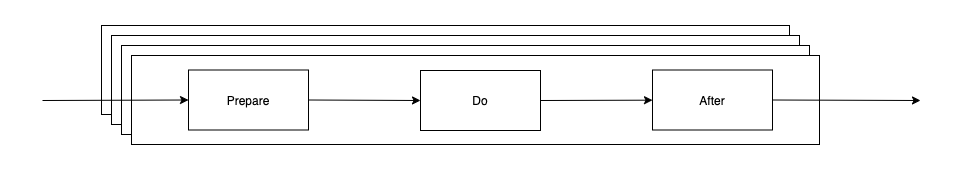
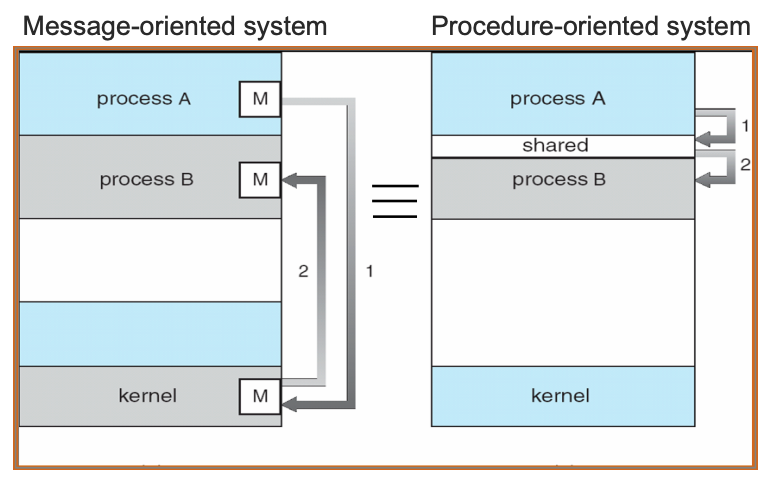
In this process, the kind of service requested is a function of which port the requesting message arrives on. It may or may not involve making requests of still other processes and/or sending a reply back to the requestor. It may also result in some circumstance, such as the exhaustion of a resource, which prevents further requests from being considered. These remain queued on their port until later, when the process is willing to listen on that port again. Note that if a whole system is built according to this style, then the sole means of interaction among the components of that system is by means of the message facility. Each process can operate in its own address space without interference from the others. Because of the serial way in which requests are handled, there is never any need to protect the state information of a process from multiple, simultaneous access and updating.
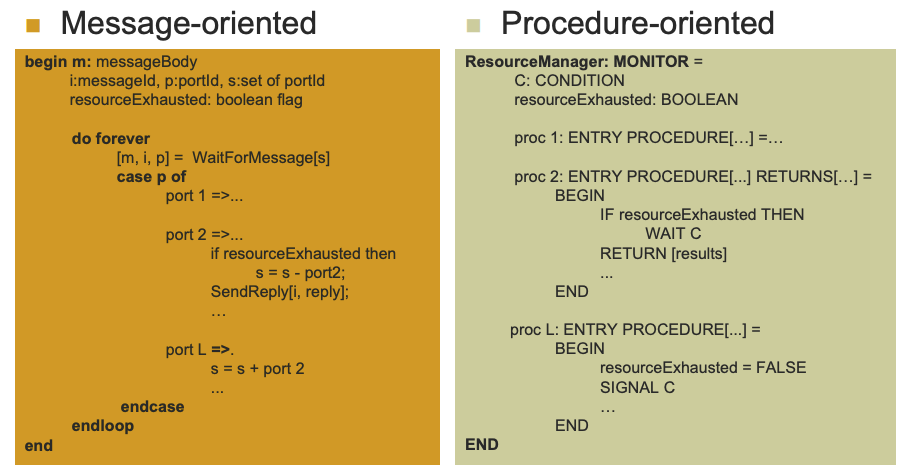
begin m: messageBody; i: messageld; p: portid; s: set of portid; ... -local data and state information for this process initialize; do forever; [m, i, p] <- WaitForMessage[s]; case p of port1 =>...; -algorithm for port1 port2 =>... if resourceExhausted then s <- s - port2; SendReply[i, reply]; ...; -algorithm for port2 portk =>... s <- s + port2 ...; -algorithm for portk endcase; endloop; end.
1. Procedures. A procedure is a piece of Mesa text containing algorithms, local data, parameters, and results. It always operates in the scope of a Mesa module and may access any global data declared in that module (as well as in any containing procedures).
2. Procedure call facilities, synchronous and asynchronous. The synchronous procedure call mechanism is just the ordinary Mesa procedure call statement, which may return results. This is very much like procedure or function calls in Algol, Pascal, etc. The asynchronous procedure call mechanism is represented by the FORK and JOIN statements, which are defmed as follows: 1) processld <- FORK procedureName[parameterList] - This statement starts the procedure executing as a new process with its own parameters. The procedure operates in the context of its declaration, just as if it had been called synchronously, but the process has its own call stack and state. The calling process continues executing from the statement following the FORK. The process identifier returned from FORK is used in the next statement 2) [resultList] <- JOIN processld - This statement causes the process executing it to synchronize itself with the termination of the process named by the process identifier. The results are retrieved from that process and returned to the calling process as if they had been returned from an ordinary procedure call. The JOlNed process is then destroyed and execution continues in the JOlNing process from the statement following the JOIN.
3. Modules and monitors. A module is the primitive Mesa unit of compilation and consists of a collection of procedures and data. The scope rules of the language determine which of these. procedures and data are accessible or callable from outside the module. A monitor is a special kind of Mesa module which has associated with it a lock to prevent more than one process from executing inside of it at any one time. It is based on and very similar to the monitor mechanism described by Hoare[6].
4. Module instantiation. Modules (including monitor modules) may be instantiated in Mesa by means of the NEW and START statements. These cause a new context to be created for holding the module data, provide the binding from external procedure references within the module to procedures declared in other modules, and activate the initialization code of the module.
5. Condition variables. Condition variables are part of Hoare's monitor mechanism an provide more flexible synchronization among events than mutual exclusion facility of the monitor lock or the process termination facility of the JOIN statement. In our model, a condition variable, must be contained within a monitor, has associated with it a queue of processes, and has two operations defined on it: 1) WAIT conditionVariable - This causes the process executing it to release the monitor lock, suspend execution, and join the queue associated with that condition variable. 2) SIGNAL condition Variable -- This causes a process which has previously WAITed on the condition variable to resume execution from its next statement when it is able to reclaim the monitor lock.
Note that because the FORK and JOIN operations apply to procedures which are already declared and bound to the right context, these operations take the same order of magnitude of time to execute as do simple procedure calls and returns. Thus processes are very lightweight, and can be created and destroyed very frequently. Module and monitor instantiation, on the other hand, is more cumbersome and is usually done statically before the system is started. Note that this canonical model has no module deletion facility.
SKIP FIGURE
The attribute ENTRY is used to distinguish procedures which are called from outside the monitor, thus seizing the monitor lock, from those which are declared purely internal to the monitor. Any of the procedures in this module may, of course, call procedures declared in other modules for other system services before returning. Within the monitor, condition variables are used to control waiting for circumstances such as the availability of resources. These are used in this standard resource manager ,tp control the access of a process the procedure representing a particular kind of service.
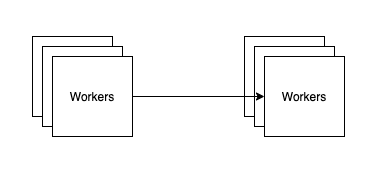
If a whole system is built in this style, then the sole means of interaction among its components is procedural. Processes move from one context to another by means of the procedure call facility across module boundaries, and they use asynchronous calls to stimulate concurrent activity. They depend upon monitor locks and condition variables to keep out of the way of each other. Thus no process can be associated with a single address space unless that space be the whole system.
一些概念的定义
Procedure
Procedure call facilities, synchronous and asynchronous
– (asynchronous):
---- processld <- FORK procedureName[parameterList]
---- [resultList] <- JOIN processld
Modules: consists of a collection of procedures and data
Monitors: 监控锁防止多进程在其中执行
Module instantiation: 实例化
Condition variables:
– WAIT condition Variable
– SIGNAL condition Variable
运行公式
ResourceManager: MONITOR = C: CONDITION; resourceExhausted: BOOLEAN; ... -global data and state information for this process
proc1: ENTRY PROCEDURE[...] = ...; -algorithm for prod proc2: ENTRY PROCEDURE[...] RETURNS[...] = BEGIN IF resourceExhausted THEN WAIT c; •••; RETURN[results]; •••; END; -algorithm for proc2 procL: ENTRY PROCEDURE[...] = BEGIN resourceExhausted <- FALSE; SIGNAL C; ...; END; -algorithm for procL endloop; endloop; initialize; END
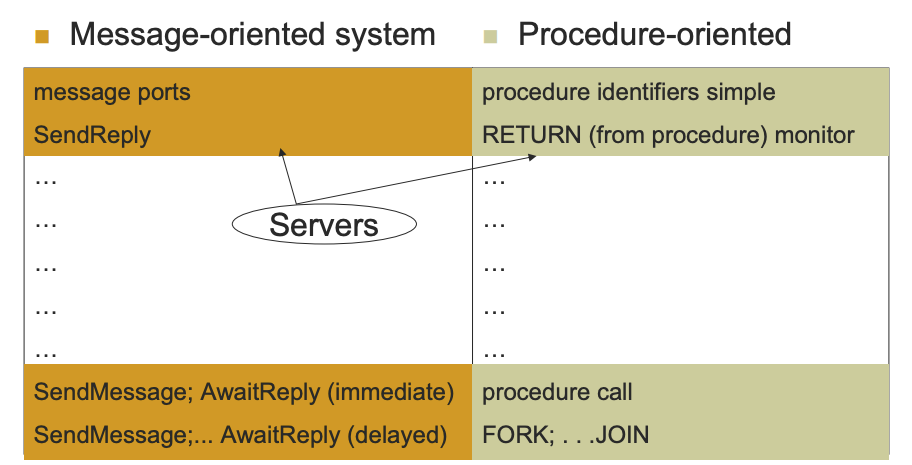
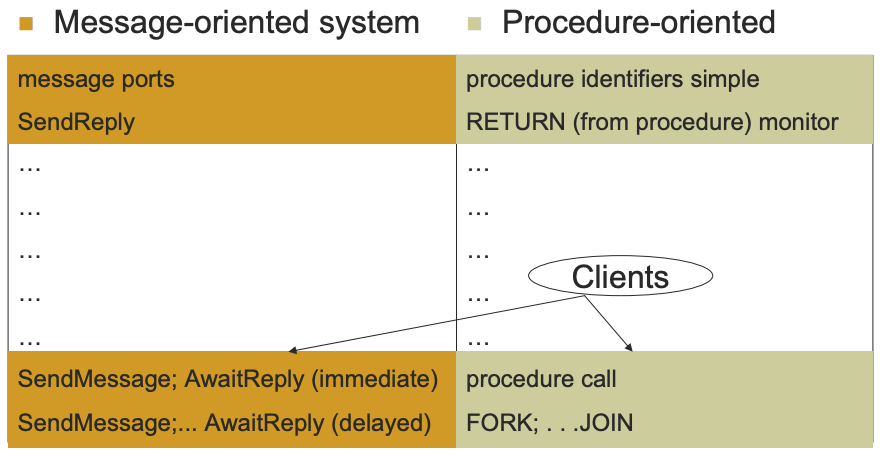
The Duality Mapping
Processes, CreateProcess
Monitors, NEW/START
Message Channels
External Procedure identifiers
Message Ports
ENTRY procedure identifier
SendMessage; AwaitReply (immediate)
simple procedure call
SendMessage; AwaitReply (delayed)
fork;join
SendReply
RETURN (from procedure)
main loop of standard resource manager, WaitForMessage statement, case statement
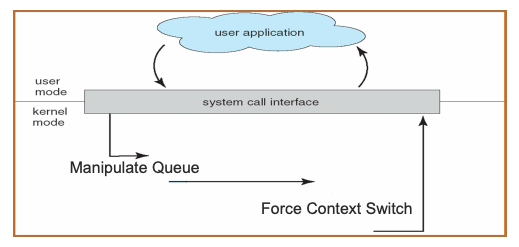
The duality transformation leaves the main bodies of the programs comprising the system untouched. Thus the algorithms will all compute at the same speed, and the same amount of information will be stored in each data structure. The same amount of client code will be executed in each of the dual systems. The same number of additions, multiplications, comparisons, -and string operations will be performed. Therefore if basic processor characteristics are unchanged, then these will take precisely the same amount of computing power, and this component of the system performance will remain unchanged. The other component affecting the speed of execution of a single program is the time it takes to execute each of the primitive system operations it calls. We assert without proof that the facilities of each of our two canonical models can be made to execute as efficiently as the corresponding facilities of the other model. I.e., Sending a message, with its inherent need to allocate a message block and manipulate a queue and its possibility of forcing a context (process) switch, is a computation of the same complexity as that of calling or FOR King to an ENTRY procedure, which involves the same need to allocate, queue, and force a context switch. Leaving a monitor, with the possibility of having to unqueue a waiting process and re-enter it, is an operation of the same complexity as that of waiting for new messages. Process switching can be made equally fast in either system, and for similar machine architectures this means saving the same amount of state information. The same is true for the scheduling and dispatching of processes at the 'microscopic' level. 14 ON THE DUALITY OF OPERATING SYSTEM STRUCTURES Virtual memory and paging or swapping can even be used with equal effectiveness in either model.